Blog
Agentic RAG: How enterprises are surmounting the limits of traditional RAG

ChatGPT launched in 2022, triggering the current AI wave, and in 2023, enterprises invested $2.3 billion in AI – an amount easily cleared by the $13.8 billion spent in 2024.
But while consumers have experimented with AI-powered chat apps and an array of AI features embedded into the many features they know and love, enterprises increasingly have their eyes set on one use case: Retrieval-Augmented Generation (RAG).
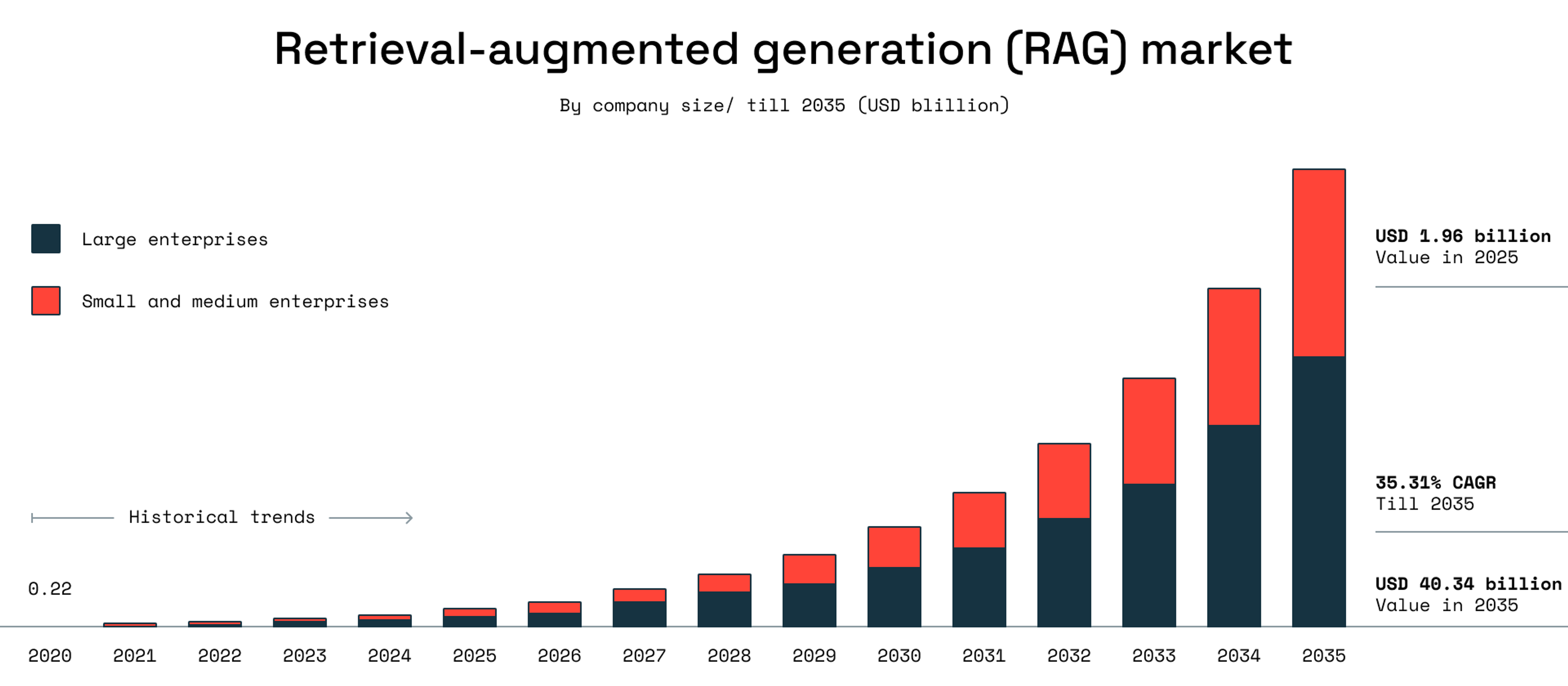
According to Roots Analysis, the market size of RAG is projected to grow from $1.96 billion in 2025 to $40.34 billion in 2035, with large enterprises leading the way in adopting it.
However, as enterprises adopt RAG, experiment with it, and iterate, they tend to find limitations. Vanilla RAG tends to be brittle, and the single-shot sequence RAG follows can be fine for simple questions and lacking for complex ones.
As these limitations become more pronounced, enterprises will seek the next step. Agentic RAG, enabled by the rise of AI agents, will be the turning point. Agentic RAG, in contrast to vanilla RAG, offers fast memory and search, semantic caching, and improved cache-hit ratios, all of which significantly improve retrieval and reduce large language model (LLM) calls.
Agentic RAG builds on the vision that first drew enterprises to RAG: offering a path to more flexible, intelligent retrieval systems. To get you up to speed, we’ll cover the basics of agentic RAG, the components that comprise it, when to use it, how to implement it, and the infrastructure you’ll need to support it.
What is agentic RAG?
Agentic RAG goes beyond traditional RAG’s single-shot retrieval-and-answer flow. It uses LLMs as agents—not just generators—that can plan steps, refine queries, invoke tools, and draw on memory. Where vanilla RAG retrieves once and passes context to the model, agentic RAG makes retrieval iterative and adaptive: the agent identifies gaps, calls the right tools, and loops until the task is resolved. For enterprises, that shift turns static lookups into dynamic, multi-step problem solving, grounded in trusted data but flexible enough to handle complexity.
The excitement around agentic RAG is best understood through vanilla RAG’s limitations.
Vanilla RAG combines an LLM with a knowledge retriever to ground the model’s output in a trusted data source. Users query via a RAG-based search feature, which triggers the retrieval of relevant documents that the LLM reads to produce and generate an answer. This process has proven effective for simple questions, but complex questions often elude traditional RAG, diminishing its usefulness.
With agentic RAG, however, the LLM isn’t a passive answer generator. The LLM takes on an active role; as an agent, the LLM can plan, act, and reason across multiple steps. Rather than merely consuming the data it retrieves, the agent can make nuanced decisions, refine its queries, and use tools to add context.
The simplest way to compare the two is to think of vanilla RAG as a static, one-shot, one-pass process, whereas agentic RAG is a dynamic, iterative process that can embrace nuance and tackle complexity.
| Feature | Vanilla RAG | Agentic RAG |
|---|---|---|
| LLM-supported | ✅ | ✅ |
| Search grounded in trusted data sources | ✅ | ✅ |
| Tool usage | ❌ | ✅ |
| Multi-step reasoning | ❌ | ✅ |
| Memory | Limited | Rich |
| Query refinement | ❌ | ✅ |
Core components of an agentic RAG system
The core components of an agentic RAG system take vanilla RAG, including LLMs with function calling, as its foundation. With the addition of agents, agentic RAG can use additional tools as necessary for any given search and use short- and long-term memory to inform its queries.
Think of the LLM in agentic RAG, as Lilian Weng, co-founder of Thinking Machines Lab, suggests, “as the agent’s brain, complemented by several key components,” including memory and tool usage.
LLMs with function calling
The LLM is the core reasoning function at the heart of an agentic RAG system. The LLM takes a prompt and produces actions, such as “search for X,” and retrieves more information. These actions can include calling a retrieval function to determine when to invoke specific tools, such as an internal vector database, calculators, web browsers, and APIs.
For example, the function call could lead to a vector store and request the retrieval of specific documents. Once the documents, in this example, are returned to the LLM, the information from the documents is fed into the LLM’s context window, enabling the agent to continue reasoning.
Many modern LLMs, including GPT-4 and Claude, can use function calling to interact with external tools. ChatGPT’s Deep Research feature, for example, can interact with numerous search tools to pull together the research materials users are looking for. There are open-source models, such as Hermes-2 Θ Llama-3 8B and Mistral-7 B-Instruct-v0.3, that provide similar function-calling features, too.
For developers, the key is to look for models that provide function calling as a built-in functionality. Technically, developers can add something approaching function calling via a combination of prompt engineering, fine-tuning, and constrained decoding, but generally speaking, native function calling tends to be much more effective.
Tools
LLMs equipped with function calling can invoke tools as necessary to complete the queries users make. Examples of tools include:
- Search engines
- Calculators
- Code interpreters
- Calendars
- Domain-specific APIs
- Web browsers
In a RAG context, the primary tool will always be the external knowledge source – typically a vector database and a wealth of internal documents – but additional tooling can transform incomplete answers into useful and impactful ones.
For example, a vanilla RAG tool might enable users to retrieve financial data from a company’s database. This might be useful for users familiar with this data, but it may be useless for non-technical users who have an important question but lack the necessary technical skills to parse the data.
With agentic RAG, the system can take the next step of invoking a Python tool to generate a chart or compute a specific statistic from the retrieved data. Agentic RAG might even be able to invoke a visualization tool to turn the data into a readable, shareable format.
Agents
An agent is an LLM with memory and a predefined role combined with the ability to plan and decompose tasks, as well as access tools.
Common agent architectures include ReAct and Plan-and-Execute, and popular frameworks include LangChain, DSPy, Letta, LlamaIndex, and CrewAI.
Planning and task decomposition
One of the primary limitations of vanilla RAG is that it tends to be one-shot, meaning that queries are run only once, and the LLM does its best in a single pass before delivering a result.
In agentic RAG, a hallmark feature is the system’s ability to plan out the process it will follow before executing it, and in doing so, decompose tasks into constituent components that it can then refine and choose between.
Agents can, in Weng’s words, “[Break] down large tasks into smaller, manageable subgoals, enabling efficient handling of complex tasks,” and “do self-criticism and self-reflection over past actions, learn from mistakes and refine them for future steps, thereby improving the quality of final results.”
Depending on the agent implementation, this planning process can emerge through prompting, including few-shot and chain-of-thought methods, or it can invoke a separate planner module.
Memory and retrieval
Agentic RAG systems maintain short-term and long-term memory to build continuity across tasks within a query and across different queries over time.
Think of short-term memory as the working notebook an agent can use to track the conversation and map the reasoning chain it’s generating. With the chat history stored in the LLM’s context window, an agent can build a more nuanced query than an LLM without that memory.
Long-term memory is a persistent store of information, generated across queries, that agents can reference over time. Many agentic RAG systems implement long-term memory with a vector store, and the agent typically stores summaries of its answers as embeddings.
Despite the usefulness of short- and long-term memory, the speed of retrieval can turn memory into a constraint. That’s why many developers turn to different, faster databases, such as Redis and DuckDB, which can store the most frequently needed data in memory, allowing for faster retrieval.
To further enhance retrieval speed, developers can also use semantic caching. Storing exact data items tends to slow down retrieval, whereas semantic caching, which caches concepts instead, can improve retrieval speed by up to 15x. This is especially effective for cost reduction because it reduces the number of LLM calls necessary to complete a query.
Best practices for memory and retrieval include implementing persistent memory solutions to prevent data loss, such as RDB and AOF, and using in-memory datastores, such as Redis, to store fast, ephemeral memory to aid recall.
Common agent roles in agentic RAG
The addition of agents to vanilla RAG isn’t a simple, linear upgrade. Agents take different roles and provide different functions, meaning that agentic RAG, once enterprises assemble a variety of agents, can equal more than the sum of its parts.
The most common agent roles include:
- Router agent: An agent that directs user queries to the most relevant tools or data sources, which enables more intelligent decision making.
- Planner agent: An agent that decomposes complex tasks into sub-tasks and orchestrates how those tasks will be executed, which enables more intricate, nuanced queries that require multi-step reasoning.
- Retrieval agent: An agent that sources and retrieves relevant information from select databases.
- Generator agent: An agent that synthesizes the final response by pulling together contextually relevant information and using both the user’s query and the retrieved information.
- Validator agent: An agent that scores and filters the retrieved information, including fact-checking, consistency analysis, relevance assessment, and error detection.
Note that agents can also include further specialized sub-roles. Validator agents, for example, can include an LLM-as-judge function that evaluates and validates the outputs of other agents.
Single-agent vs. multi-agent architectures
Agentic RAG is most effective when enterprises can integrate multiple agents, each with distinct roles and functionalities, to collaborate on addressing complex queries. Enabling this approach, however, requires a different architecture – one that is multi-agent instead of single-agent.
Single-agent architectures aren’t without their use cases, however. An enterprise might prefer a single-agent approach to relatively simple problems, such as adding an LLM agent that can better route queries or an agent that can more effectively retrieve information.
Multi-agent architectures can also introduce more complexity and harder-to-diagnose failure modes, so if an enterprise prefers simplicity or lacks the resources to support multi-agent systems, single-agent architectures can be a good choice.
In a multi-agent architecture, enterprises can rely on a master agent to delegate tasks to agents with different roles, including the retrieval, planning, and generator agent roles described above.
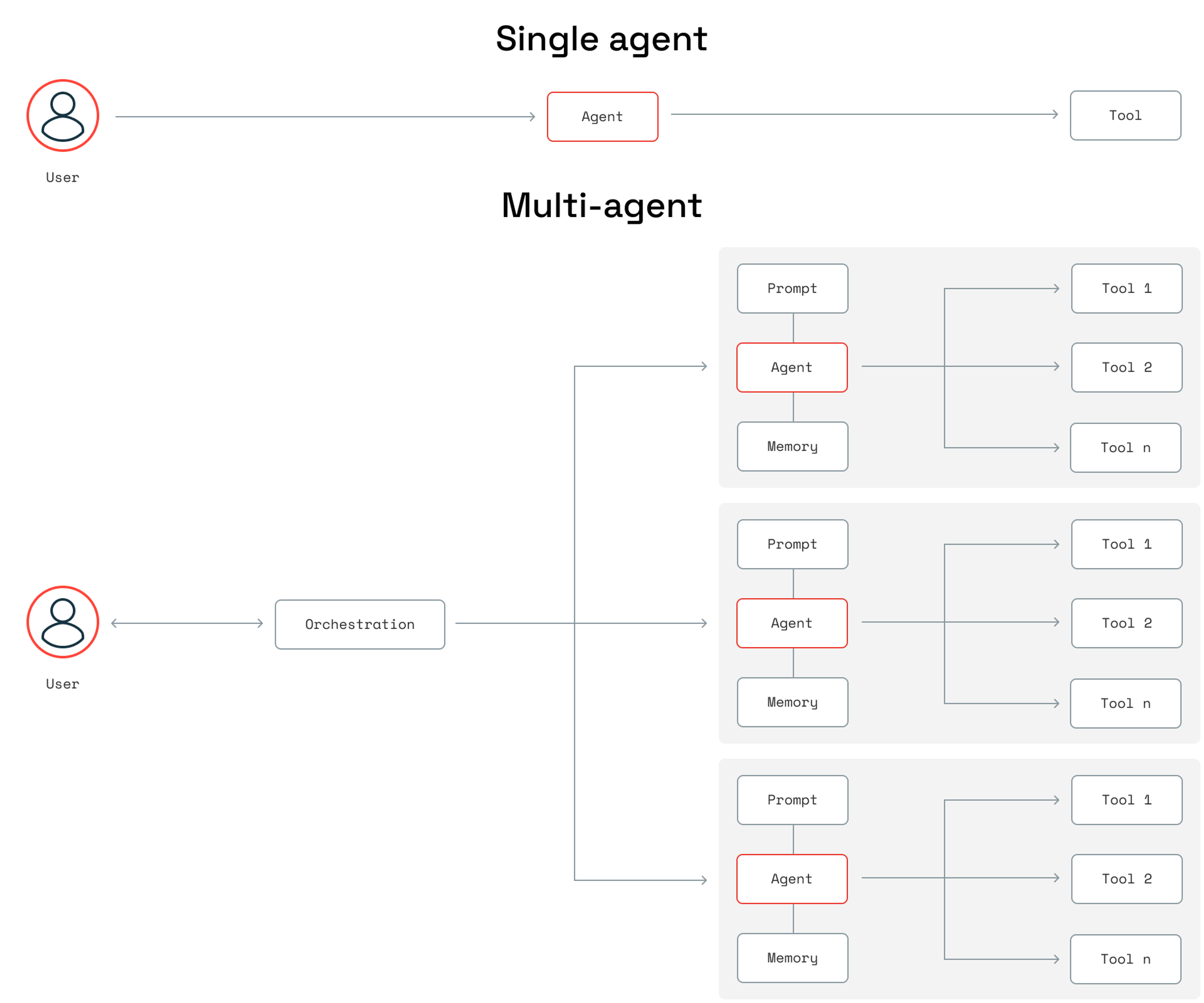
With the right infrastructure, enterprises don’t have to pre-decide between single- and multi-agent approaches. Redis, for example, can support both architectural approaches, offering in-memory data to support lightweight memory or context stores.
Benefits of agentic RAG
Implementing agentic RAG isn’t as simple as implementing vanilla RAG, but it provides a range of benefits that most enterprises interested in the promise of RAG will find worth the investment.
Better retrieval and more accurate responses
The core reason many enterprises implement RAG at all is to increase accuracy. Ask a generic LLM about your company’s internal data, and it won’t be able to help. RAG solves this by grounding answers in that data.
Agentic RAG takes this a step further, using better retrieval to generate much more accurate responses. If enterprises want RAG to support important decisions with real business impact, then accuracy is of the utmost importance. As DHH, co-founder of 37Signals, writes, AI features need to be better than humans: “As good as a human isn’t good enough for a robot. They need to be computer good. That is, virtually perfect. That’s a tough bar to scale.”
If users learn that RAG answers aren’t trustworthy, they’re likely to return to the default of manually searching for information.
Context validation and re-retrieval
In vanilla RAG, queries run once and return results that may or may not be satisfactory. With agentic RAG, agents can use context validation to assess whether the retrieved information answers the query, and re-retrieval to try retrieval again in the event the initial attempt doesn’t yield workable results. Together, these features allow agentic RAG to recognize when it fails and try alternative pathways to better responses.
Multiple tools and smarter decisions
A vanilla RAG system is limited by the LLM it relies on and the database it retrieves information from. Agentic RAG, in contrast, can call on multiple tools to inform its search and its queries. This ability goes far beyond adding details from an online search; with access to external tools, the entire search process can be much more nuanced given context from the tools it’s accessing.
Continuity and personalization
A vanilla RAG system doesn’t always include memory, meaning that users will always be performing fresh searches, and the RAG system will always be starting over from scratch. Agentic RAG can rely on long-term memory to build on successes, failures, and feedback from the past. As a result, RAG results can improve, and users can develop trust with its increasing accuracy.
Multimodal workflows
Vanilla RAG tends to be text-based, which means it’s limited to data that can be captured in text formats. If the primary use case is enabling users to query private company documents, vanilla RAG won’t be able to capture information from graphs, diagrams, and other images.
Agentic RAG, supported by multimodal agents, can search across different formats, including text, images, and audio, and use computer vision to analyze unparsed documents, such as PDFs. Agentic RAG can even integrate with APIs to add many other functions as necessary.
Tradeoffs and limitations of agentic RAG
Agentic RAG isn’t a silver bullet: There are tradeoffs, limitations, and costs involved, and interested enterprises should take care to evaluate these downsides and figure out ways to address them.
Latency
Agentic RAG can sometimes encounter latency issues because agents add more steps, which can result in longer response times between them. Generally, developers can best reduce latency by caching intermediate results and fast state lookups. Relevant tools include:
- Redis: Ideal for fast, in-memory caching, Redis can provide intermediate results and semantic retrievals to reduce latency.
- GPTCache: This open-source semantic caching tool reduces latency by serving previously computed LLM responses to semantically similar queries.
- FAISS: This tool provides efficient, low-latency embedding retrieval and nearest-neighbor searches, which are especially effective when combined with tools like Redis, which enable fast state lookups.
There’s a balance to strike. If queries and responses tend to be simple, then the latency involved in agentic RAG might be too big a tradeoff. However, in most cases, the benefits of agentic RAG make it worthwhile to explore ways to mitigate any potential latency.
Cost
Agentic RAG benefits from multi-step reasoning that involves numerous calls to LLMs via numerous agents. The downside of this benefit is that more tokens can result in higher costs. Caching tools can reduce costs by cutting down repeated LLM calls. Relevant options include:
- Redis Semantic Cache (via LangChain): This tool caches previous LLM outputs and reuses those responses for similar queries, significantly reducing token consumption.
- GPTCache: This tool provides semantic caching, which can reduce the frequency of LLM calls and lower usage costs.
- LangChain’s Function-Call Caching: This feature deduplicates external tool invocations, enabling enterprises to avoid costly, repetitive API calls.
Without the right care around design, LLM usage can become very expensive – a problem that extends far beyond agentic RAG. Any enterprise that wants to make extensive use of generative AI will have to address the possibility of mounting costs.
Reliability
Agentic RAG can include numerous different agents, but agentic RAG can sometimes suffer from reliability issues if any of those agents fail or loop. Developers can reduce the likelihood of these issues happening by implementing fast fallback mechanisms. Relevant tools include:
- Cloud provider reliability tooling: This category of tools, including ones from Azure, Google Cloud, and Amazon Web Services, ensures that systems can temporarily stop calls and reroute to backups.
- LangChain: This tool provides built-in iteration limits, retry mechanisms, and structured fallback logic, ensuring that agents won’t endlessly loop.
- Apache Airflow: This tool offers centralized orchestration with built-in retries, timeouts, and failover strategies for agent tasks.
With fallback mechanisms like these in place, enterprises can be much more confident that the agents involved in agentic RAG systems can operate without failing.
Complexity
Agentic AI, because it involves adding numerous agents to a more foundational RAG approach, can be harder to debug, observe, and monitor than vanilla RAG. Developers can make agentic RAG easier to manage by adding fast and transparent caching solutions that simplify debugging and monitoring work. Relevant tools include:
- LangSmith: This specialized tracing tool provides step-by-step visibility into agent reasoning, tool usage, latency, and errors.
- Langfuse: This open-source observability platform enables the tracing of agent interactions, LLM calls, and the capture of structured logs.
- Datadog, Prometheus, or Grafana: These general-purpose monitoring and logging solutions enable the tracking of structured agent metrics, logs, and performance indicators.
Agentic RAG can be complex to implement and manage, but enterprises, after facing the limitations of vanilla RAG, are increasingly choosing to face the complexity and find the right tools to make agentic RAG more manageable.
Overhead
Agentic RAG, due to its integration of numerous AI agents, can lead to coordination issues and potentially incur overhead. Developers can address this by using active-active setups – high-availability architectures using multiple nodes to operate concurrently – to better handle scalability. Relevant tools include:
- Redis: This tool, particularly its shared memory and pub/sub features, enables real-time shared memory between agents, facilitating fast coordination and event-driven communication.
- Apache Kafka: This tool provides a scalable message broker for asynchronous, decoupled event-driven communication among multiple agents.
- Ray or Apache Airflow: These frameworks provide centralized orchestration, task scheduling, and robust coordination for complex multi-agent workflows.
Some amount of overhead is likely in a more complex setup, as in agentic RAG versus vanilla RAG. However, as enterprises struggle with vanilla RAG, the possibility of overhead tends to feel more like a challenge worth addressing than a risk worth avoiding.
Infrastructure considerations for agentic RAG
Agentic RAG offers significant potential for enterprises, but much of that value is only accessible when these systems can rely on the right infrastructures. To make the most of agentic RAG, design systems that are:
- Low latency: Invoking different agents or parts of the system can cause latency issues, so the infrastructure needs to be able to reduce latency as much as possible.
- Scalable: Agentic RAG is most effective when systems use multiple agents at once, and as agentic RAG systems scale, the increasing amount of inter-service calls and dependencies among agents can make debugging and system reasoning more challenging. As a result, agentic RAG is most effective with infrastructure that can scale to handle many agents at once.
- Flexible: Agentic RAG is most effective when it can operate across multiple modalities, so infrastructure that supports various data types, including text, vectors, and structured data, is most suitable.
Redis can provide numerous infrastructure-level benefits that help with agentic RAG, including:
- Real-time memory, which can support short- and long-term memory for RAG agents.
- High-speed vector search and hybrid queries to support fast, nuanced queries and retrievals.
- Multi-region availability for geo-distributed agents, which increases scalability.
- Semantic caching to reduce redundant lookups and decrease costs.
Agentic RAG is becoming an increasingly popular topic, but the focus of these conversations tends to be on designing or orchestrating agents. The realities of production, however, show that these systems’ failure points tend to be lower in the stack.
Memory, coordination, and retrieval latency issues can all make agentic RAG too slow or too cumbersome to be practical. With every agent calling tools, fetching context, and validating results, the real bottleneck tends to be an enterprise’s infrastructure, especially under high throughput.
Build the future of retrieval with Redis
Agentic RAG is powerful, but it may not be the right fit for every RAG use case. For teams ready to experiment, agentic RAG offers adaptability, depth, and context control. For enterprises that are trying RAG but feel limited, agentic RAG offers the possibility to fulfill the potential they originally saw in RAG.
An enterprise’s infrastructure choices play a key role in addressing agentic RAG issues. Infrastructure bottlenecks are risky, especially under high throughput, and Redis is the ideal solution for ensuring an enterprise’s infrastructure doesn’t become a limiting factor. Redis also makes it easier and faster to align data structures with applications, further increasing cache hit ratios.
Objective benchmarking reveals that Redis outperforms all other vector databases, making it the fastest option for agentic RAG, a use case that requires speed and scalability.
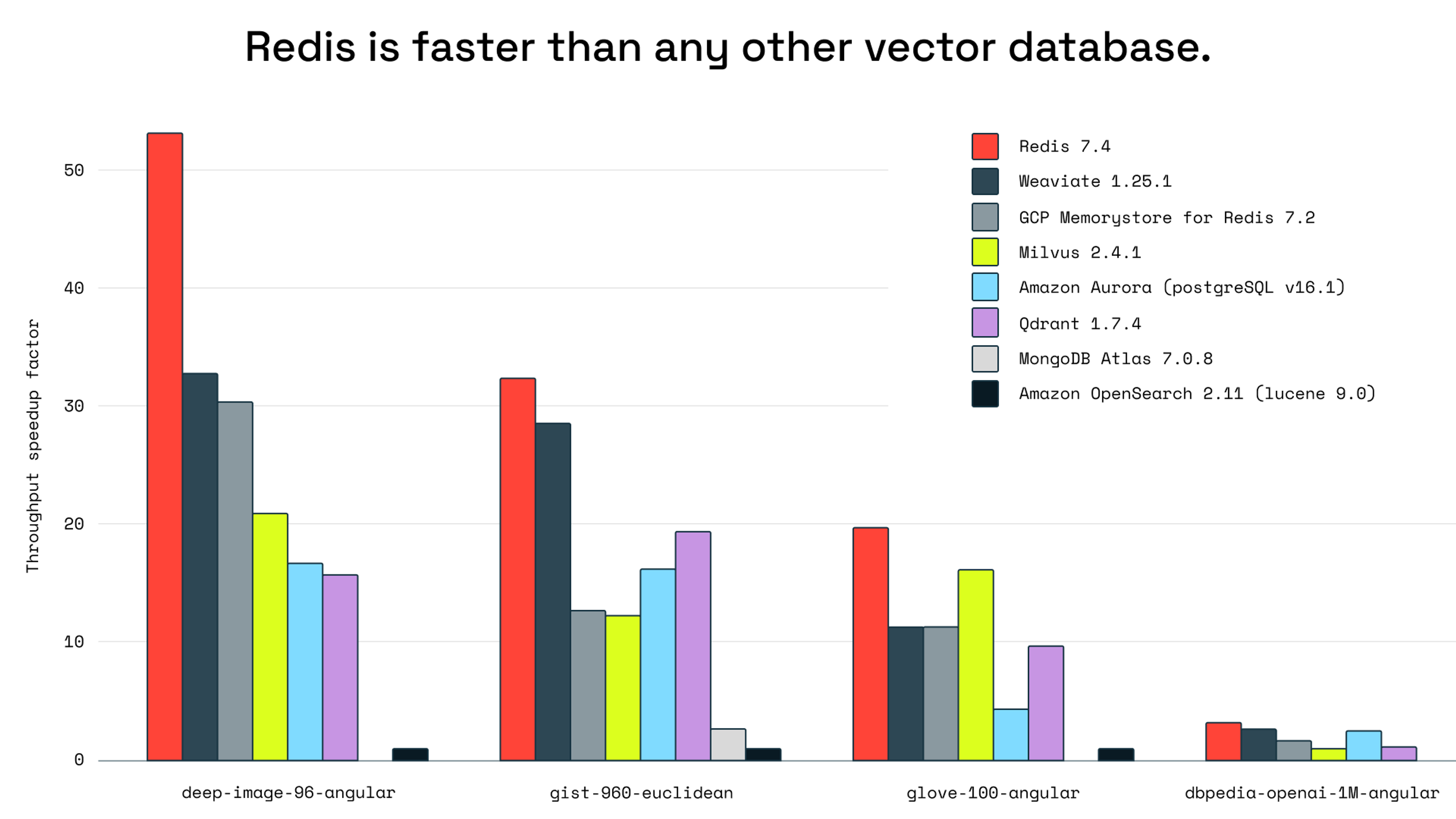
If you’re ready to build an agentic RAG system or support an existing one with faster, more reliable infrastructure, you can try Redis for free or book a demo today.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.