
What is LLM chunking?
LLM chunking is the practice of splitting large data into smaller, self-contained pieces before feeding it to a model. Think of how you remember a phone number: it’s easier in parts—area code, first three digits, last four—than as one long string. LLMs benefit from the same approach. With chunking, each piece becomes a manageable unit in the context window, so a RAG system can pull only the most relevant chunks into the prompt instead of passing the entire document.
Done well, chunking boosts accuracy, reduces latency, and keeps token costs in check. Done poorly, it dilutes context, inflates costs, and frustrates users. This article covers the main chunking strategies, common pitfalls, and how Redis helps enterprises get it right at scale.
LLM chunking strategies
Not all chunks are created equal.
In the same way that you’re more likely to remember what you need from the grocery store if you memorize the items by where they are in the store instead of by order in the alphabet, LLM chunking works best when the chunks preserve context and semantic meaning.
A good LLM chunking strategy optimizes for accuracy and relevance when retrieving information from a vector database by embedding text that preserves meaning while minimizing extraneous noise. By splitting data into smaller but still semantically meaningful pieces, chunking retrieves only the information relevant to a user’s query and sticks closer to the LLM’s token limit.
As a result, chunking:
- Improves context relevance because the model only sees information related to the query.
- Boosts accuracy because the model ignores irrelevant text that’s more likely to cause confusion or hallucination.
- Increases retrieval efficiency because the model focuses the query on only the necessary information.
When companies get results from LLMs that don’t have the right context or provide inaccurate information, the root cause likely isn’t the model – it’s how the data was chunked. Effective chunking organizes data to improve accuracy, relevancy, and efficiency; ineffective chunking does the same, but to a very limited extent, meaning the issue can only appear to be solved.
Chunking is especially important for RAG purposes because the value of RAG is dependent on the accuracy of its results. Harder still, the accuracy has to well exceed the accuracy of a human doing manual work. As DHH, co-founder of 37Signals, writes, “Being as good as a human isn’t good enough for a robot. They need to be computer good. That is, virtually perfect. That’s a tough bar to scale.”
If you’re running into accuracy and retrieval problems, then look at your chunking strategy and check to see whether your issues might be downstream. With high-speed vector stores and hybrid search, such as the features Redis provides, you can ensure chunking is semantically precise.
Often, especially with systems not supported by high-speed vector stores and hybrid search, such as Redis, disappointing results can result from a chunking strategy that isn’t semantically precise.
Common LLM chunking use cases and applications
Chunking is very common at its most basic level, but highly effective chunking can be the difference between a generic application and an application that is truly scalable.
Basic chunking can be good enough in small-scale use cases, but where scale is necessary, more advanced chunking is needed. To see effective chunking strategies in action, look to use cases and applications where accuracy needs to be able to keep up with scale, including:
- Conversational AI: In these situations, which include use cases like customer service chatbots, effective chunking can reduce latency and improve response accuracy. Chunking can be the difference between a chatbot with customers begging for a human agent and customers satisfied with a promptly given, full, and complete answer. OpenAI’s Assistants API, for example, includes a file search feature for automatically parsing and chunking documents.
- Semantic search engines: In these use cases, chunking improves content retrieval precision and reduces costs, ensuring that search can scale without overburdening infrastructure or budgets. Palantir, for example, offers a semantic chunking feature to support semantic search for use cases like legal document analysis.
- Content generation tools: In these applications, which include use cases like automatic content summarization, chunking enhances the coherence and relevance of generated content. LangChain, for example, uses chunking to support orchestration via LangGraph and to provide summarization capabilities. Combined with Redis, Langchain can even support semantic image-based queries.
Across these use cases, chunking can be made even more effective with the right infrastructure, which is especially necessary at large scales or fast speeds. If you want conversational AI that works from real-time memory to provide real-time response speeds, for example, a tool like Redis can be necessary to make your chunking strategy come together.
Popular LLM chunking strategies
Chunking, because it’s so common and expected in even basic LLM and RAG setups, often goes underexamined. But overlooking chunking is like assuming a sports car is ready to race just because it technically has tires. If you want to race and win, you need tires suited for the job.
Similarly, the right chunking strategy ensures optimal context preservation and enhances the relevance and coherence of model outputs. In contrast, the wrong strategy can result in context loss, increased latency, higher operational costs, and ultimately, poorer user experiences.
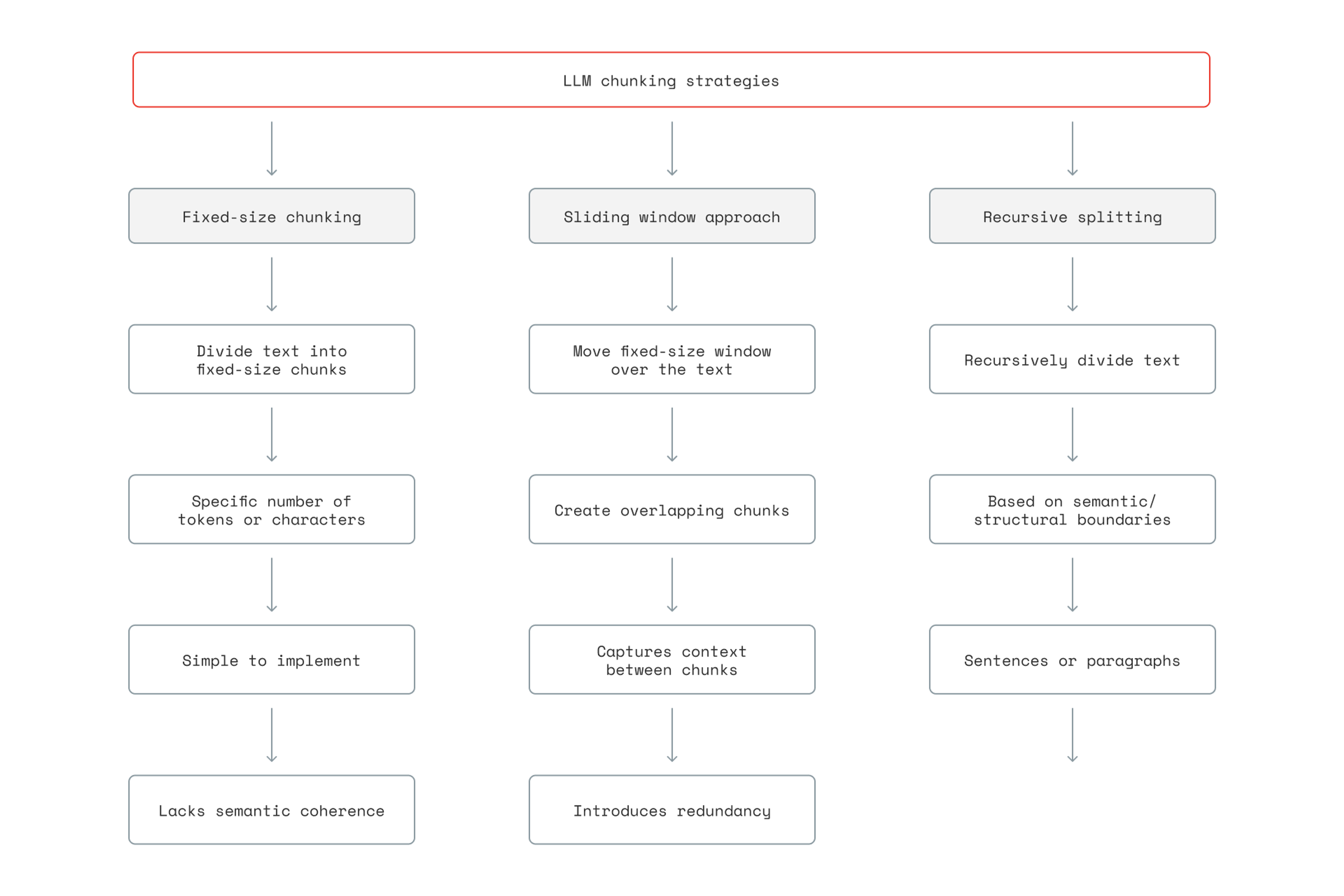
1. Fixed-length chunking
Fixed-length chunking splits text into uniform chunks based on simple metrics, such as token count, word count, and character count. This strategy ignores sentence and contextual boundaries in favor of uniform segment sizes.
This chunking strategy is relatively simple to implement, and it ensures each chunk is below a certain chunk size, which is helpful for fitting queries into context windows and reducing token costs. Its simplicity means it’s fast to implement, requires no complex natural language processing (NLP) knowledge, and offers a predictable computational load.
That said, this simplicity can be a double-edged sword because it often causes context to be arbitrarily split. Fixed-length chunking often cuts sentences apart or splits closely related paragraphs. Similarly, because fixed-length chunking doesn’t respect semantic boundaries or differences, it can treat one 100-word segment the same as another, even if one contains a full thought and another contains two unrelated topics.
2. Semantic chunking
Semantic chunking splits text based on meaning and natural boundaries, with the goal that every chunk becomes a semantically coherent unit.
When using semantic chunking, you can further dial in your preferences through sentence-based chunking (sentences and groups of sentences), paragraph and section chunking (paragraphs, sections, and parts of a document split by headings), and adaptive semantic chunking (where embeddings and machine learning find the boundaries between chunks).
The former two approaches have similar limitations: Sentences and sections can each vary in length and information density, resulting in unpredictable token counts.
Overall, semantic chunking produces chunks that tend to be thematically or topically connected, not arbitrarily divided from each other, as in fixed-length chunking. As a result, semantic chunking can be very effective for use cases that require preserving context and maintaining high accuracy, such as RAG.
That said, semantic chunking can be complex and costly. It’s also easy, without the right fine-tuning, to split data into too many tiny chunks or split data into too few, less related chunks.
Worse, without the right infrastructure, you can end up re-embedding the same chunks over and over again, reducing efficiency. With Redis as a vector database, however, you can cache embeddings and use chunks more effectively. The Redis Vector Library, for example, offers an AI-native Python client library with a deep array of real-time data features that you can use to power your applications.
3. Hybrid approaches
Hybrid chunking, as the name suggests, is a combination of fixed-length and semantic chunking. The goal of this approach is to capture the benefits of both approaches while reducing the tradeoffs.
Fixed-length chunking, as we covered above, is computationally cheap but can arbitrarily break the context of the data you’re retrieving. Semantic chunking leads to more meaningful chunks, but it has a higher cost and requires greater complexity. Hybrid approaches balance the two by preserving the structure of the captured information as much as possible while enforcing length limits.
Particular types of hybrid approaches include:
- Recursive/hierarchical chunking, which splits text across multiple passes by a pre-set hierarchical structure. This approach might break a text down into chapters and then sections and then paragraphs, until the most meaningful unit possible can fit into the token limit.
- Slide window chunking, which uses a window of, say, 200 tokens, and slides that window to the next 200 tokens such that 50 tokens overlap each other. This creates redundancy, which has the upside of increasing accuracy and the downside of storage costs.
- Agentic chunking uses an LLM to make chunking decisions as the text is processed.
Overall, hybrid chunking tends to be best when scalability is paramount, such as enterprise-scale search engines or highly context-dependent conversational AI systems. At large enough scales, fixed-length chunking can be too simplistic, and semantic chunking can be too costly.
Hybrid search, however, can be difficult to implement without the right infrastructure supporting you. Redis handles hybrid chunking by combining exact match, full-text, and vector search, which supports a full-text search platform that ensures queries account for context, synonyms, and word proximity. This holistic approach allows queries to capture the relevant, accurate results.
See how Redis makes chunking fast and scalable. Try it free.
Challenges with inefficient chunking
Ineffective chunking introduces issues into your LLM application, but the biggest risk is how those issues interact. The wrong strategy won’t just be less than effective; it can create a chain reaction that leads to inaccuracy, inefficiency, and more.
The three primary challenges include:
- Inaccurate responses and hallucinations: Bad chunking can degrade the quality of the answers you’re retrieving. Models can answer incorrectly if a critical piece of context is in an unretrieved chunk, or, worse, the model could hallucinate to fill in the missing information.
- Context overflow: Despite the risk of inaccurate responses, more isn’t always better. Chunks so big that they contain irrelevant information can cause imprecise, unfocused, distracted answers. At its worst, too much context can cause context overflow, which causes the model to run out of space for its own reasoning.
- High latency and high throughput costs: Meanwhile, as the system struggles to find a balance between too small chunks causing inaccuracy and too big chunks causing overflow, latency and throughput costs can rise. Inefficiency chunking is often the result of chunks that are too small, requiring the system to perform extra work for each query, or chunks that are too large, making each retrieval slower.
It’s a tough balance to strike. A chunking strategy that leads to too big chunks can cause high latency and context overflow, and a strategy that leads to too small chunks can cause throughput costs and inaccurate responses.
If a RAG system is reliant on such imbalance chunking strategies, the user experience is likely to degrade, and infrastructure issues are likely to increase. Without the right upfront strategy, costs can spiral.
How Redis supports effective chunking
Redis supports chunking across a range of Redis products, including Redis Cloud, Redis Software, and Redis Community Edition. Redis also integrates with LangChain, providing users with an easy way to make chunking available through Redis’s open-source partner package and Redis Vector Library.
Redis as a vector database for semantic chunking
Redis Vector Database provides essential infrastructure for advanced semantic chunking strategies, which can significantly enhance retrieval accuracy and operational efficiency in applications using GenAI.
Traditional caching focuses on keyword matching, but Redis provides semantic caching, allowing a search feature, for example, to recognize that “comedy movie” and “funny movie” are similar terms. A study across 20 ChatGPT users and over 27K queries showed that “31% of user queries were similar to previous ones, suggesting a user-centric cache can reduce LLM inference costs.”
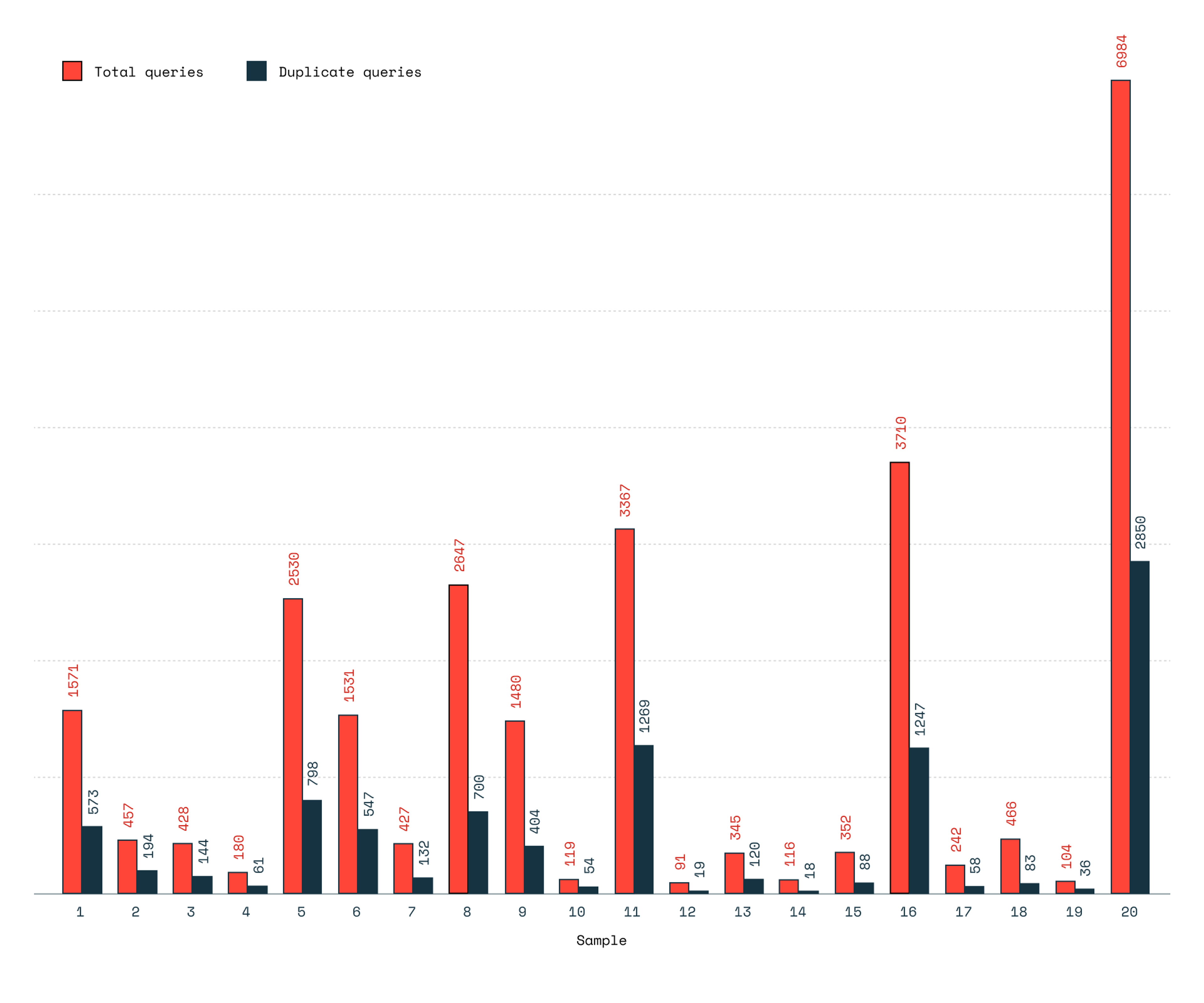
Depending on the particular use case at hand, query similarity might rise even further, making caching even more effective.
Redis for chunk management and retrieval
Redis supports chunk management and retrieval through Redis Enterprise, which stores and indexes domain-specific data as vector embeddings.
When users execute a search, vector similarity search uses the user’s query to retrieve only the most relevant chunks, ensuring the eventual LLM outputs suit the query and the context. This improves LLM performance, especially in RAG applications, and helps users maintain confidence in the retrieved answers.
This is especially useful for companies pursuing a hybrid search capability because Redis can support the balance of numerous chunking strategies. As Tyler Hutcherson, an AI engineer at Redis, wrote, “The most effective retrieval solutions don’t choose one over the other. Instead, they often implement some form of hybrid search.”
Redis as a backend for real-time AI applications
Redis can function as a memory layer for AI applications, allowing them to achieve lower latency even as they increase throughput.
With Redis data structures and vector search, for example, companies can increase the amount of memory an LLM has across sessions, allowing for greater personalization and enhanced context awareness.
With past conversations already loaded and speedily retrievable, LLMs supported by Redis tailor their responses to user needs and preferences. Similarly, with greater context awareness, LLMs can build on knowledge from previous conversations.
Case study: Docugami
Docugami is a leader in providing AI tools for business documents, allowing businesses to use LLMs to free data from corporate documents and enable users to easily use that data to generate reports, build new documents, and find insights that might otherwise stay hidden.
To scale, Docugami needed a distributed services architecture that its patented AI system could use to process large workloads while maintaining high accuracy and fast response times. Docugami turned to Redis to provide a cache for speeding up processing and a vector database that could accelerate GenAI tasks.
“Redis is the cornerstone of our service infrastructure, helping us to deliver Docugami’s enterprise-ready, industry-leading precision and accuracy at scale, with exceptional response times and affordability,” says Jean Paoli, CEO at Docugami.
Docugami is also a leader in providing RAG services through its KG-RAG (Knowledge graph-RAG) approach, which uses exclusive hierarchical semantic chunking. Redis supports Docugami’s RAG strategy, helping Docugami achieve sub-second retrieval and enterprise-scale throughput. With high-performance, low-latency data retrieval and the ability to store embeddings of documents, knowledge bases, and business content in a vector database for rapid retrieval, Docugami has the architecture it needs to support RAG.
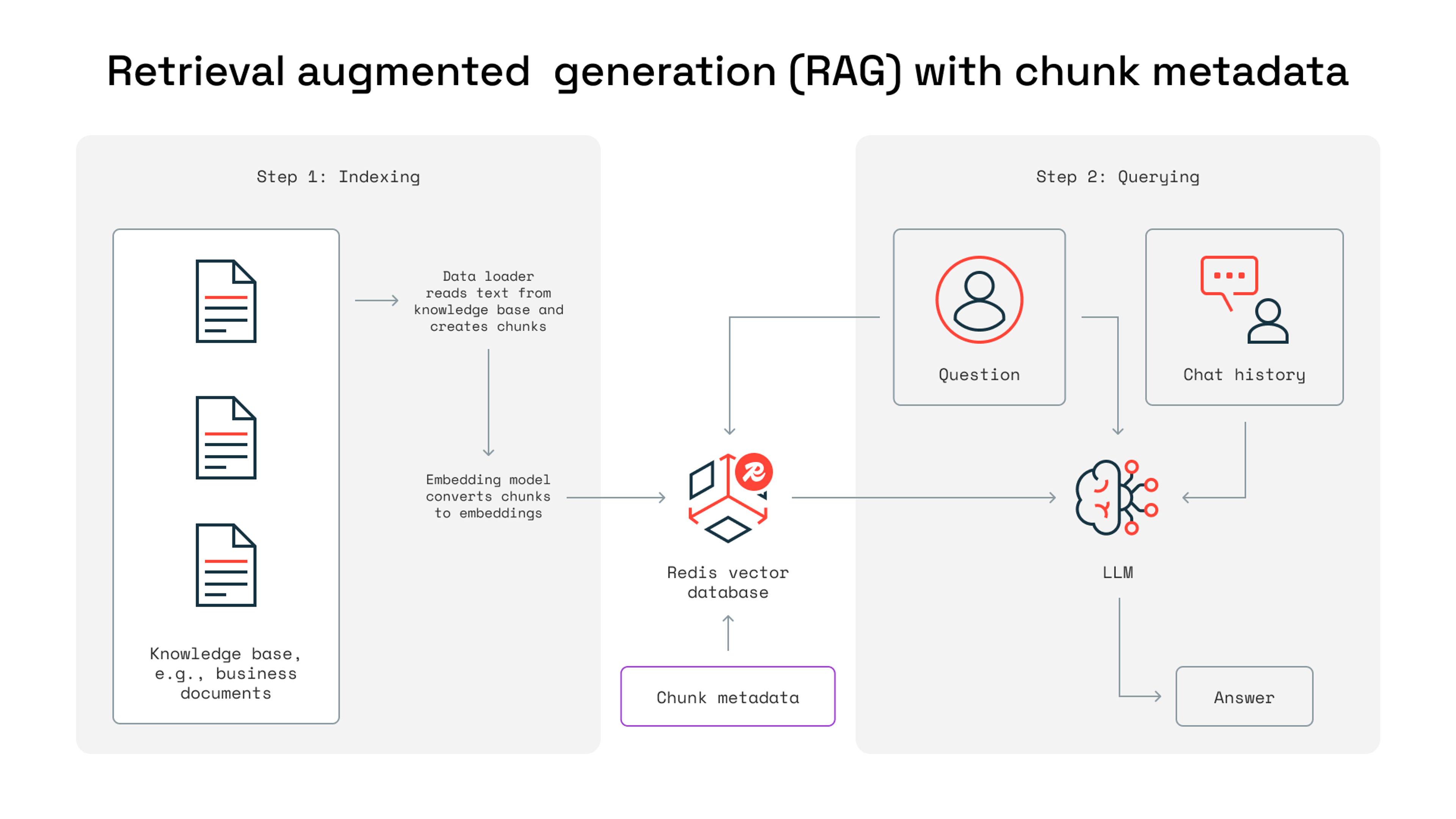
“Our new architecture, powered by Redis, facilitates the rapid processing of tasks at scale, enabling the real-time interactions that our customers expect, particularly as they are chatting with their document data,” says Mike Palmer, co-founder and head of technologies at Docugami.
Optimize your LLM chunking strategy with Redis
Effective LLM chunking is often the difference between accurate, performant, efficient models and slow, hallucinating ones. In RAG use cases, especially, chunking can be make-or-break for the RAG providing enough value to be well adopted.
Ultimately, there is no one-size-fits-all chunking strategy. You need the flexibility to identify the right chunking strategy for your use and the right infrastructure to support iteration across strategies.
With Redis, you can seamlessly integrate the right infrastructure into your LLM workflows. Redis enables real-time chunk management by storing preprocessed chunks, indexing them via vector search, and serving relevant chunks with low latency. If you’re looking to enhance chunk management, boost retrieval speed, and improve context retention, Redis might be the missing piece.
Try Redis free or schedule a demo today to see firsthand how Redis can transform your AI infrastructure.
And if you want to dive deeper, watch this short video walk through on how to chunk data for better LLM retrieval, which covers real examples, tradeoffs, and best practices in action.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.