
In the last article, we introduced the retrieval optimizer, why it matters for eval driven development (EDD) and how to get started with a basic grid search. Often selecting the right search method and embedding model are the most influential elements that need to be measured first. However, there are many search index settings that have a tangible impact on the performance of your information retrieval app.
The problem is that to test all the available permutations of these settings would take too much time. This is where Bayesian optimization comes in. Instead of testing every possible combination of hyperparameters, Bayesian optimization chooses the best ones to try next based on what it has already learned. This greatly reduces the number of experiments needed. You don’t need to dive into the math behind Gaussian processes. Just define what matters most to your app (e.g. recall, latency, or precision) as an objective function (see below), and the optimizer will guide the search toward configurations that maximize your chosen objective.
Code example
Running a bayesian optimization study with the retrieval optimizer is very similar to running a grid study.
📓You can find the complete notebook example here.
Gather dependencies
Install tool:
Run redis:
Pull and/or create study data
As we did in the grid study, we’ll pull the data for our experiment from the beir benchmarking IR datasets and save to respective files.
Define study config
The study config determines the ranges and values that the optimization process can choose to select while it seeks to maximize the objective function.
The metric_weights define how much each parameter is weighted in the objective function. In the following example, the resulting objective function will be:
If a metric, such as recall_at_k isn’t indicated in the metrics weights, its assumed value will be 0. Therefore, in this hypothetical study, we’ll choose settings that equal weight improvements for f1_at_k and total_indexing_time.
Execute study
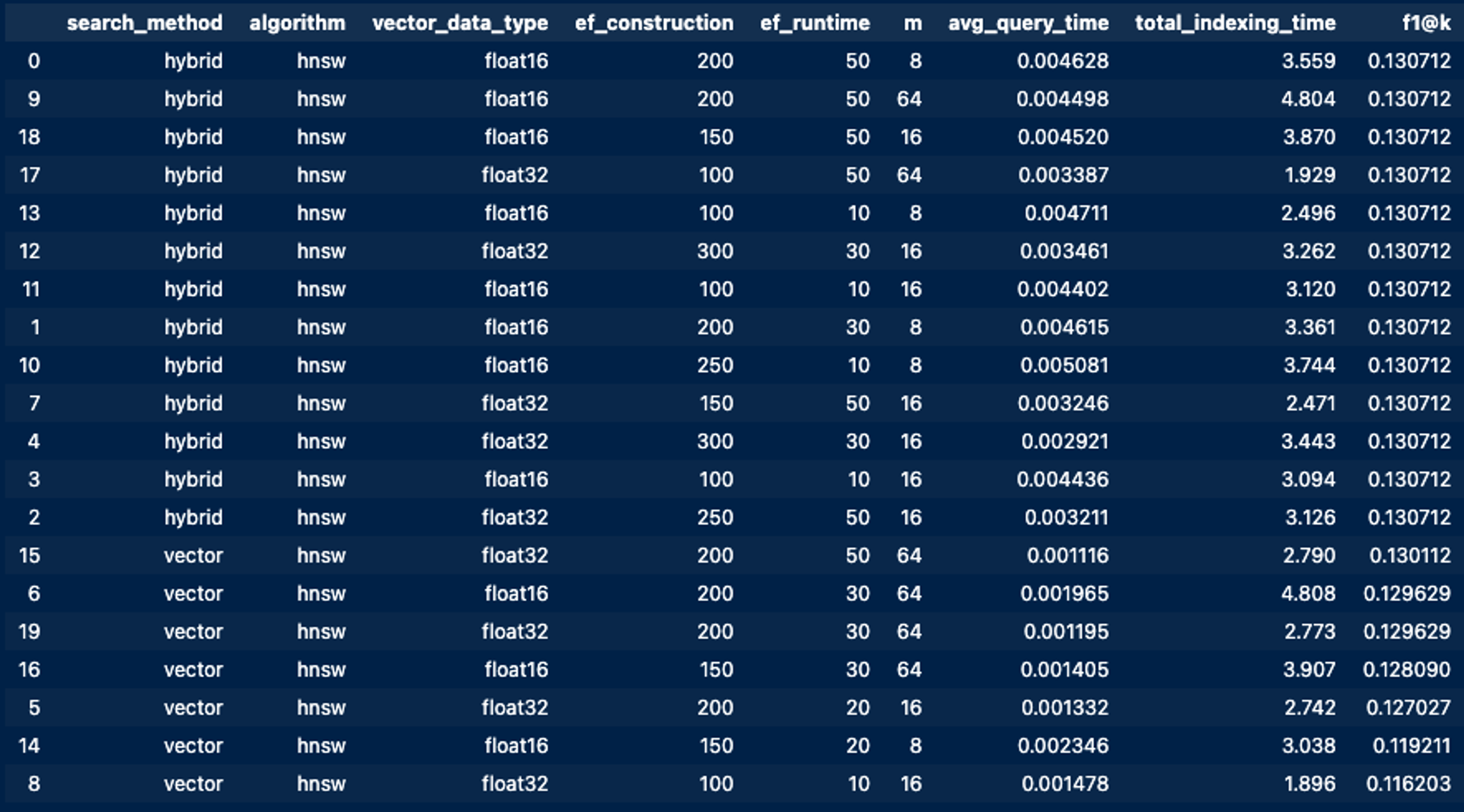
Output example
As you can see from the output, the process selected options (such as a smaller m param and vector_data_type) to reduce footprint and bring down indexing_time while maintaining or improving the f1 score.
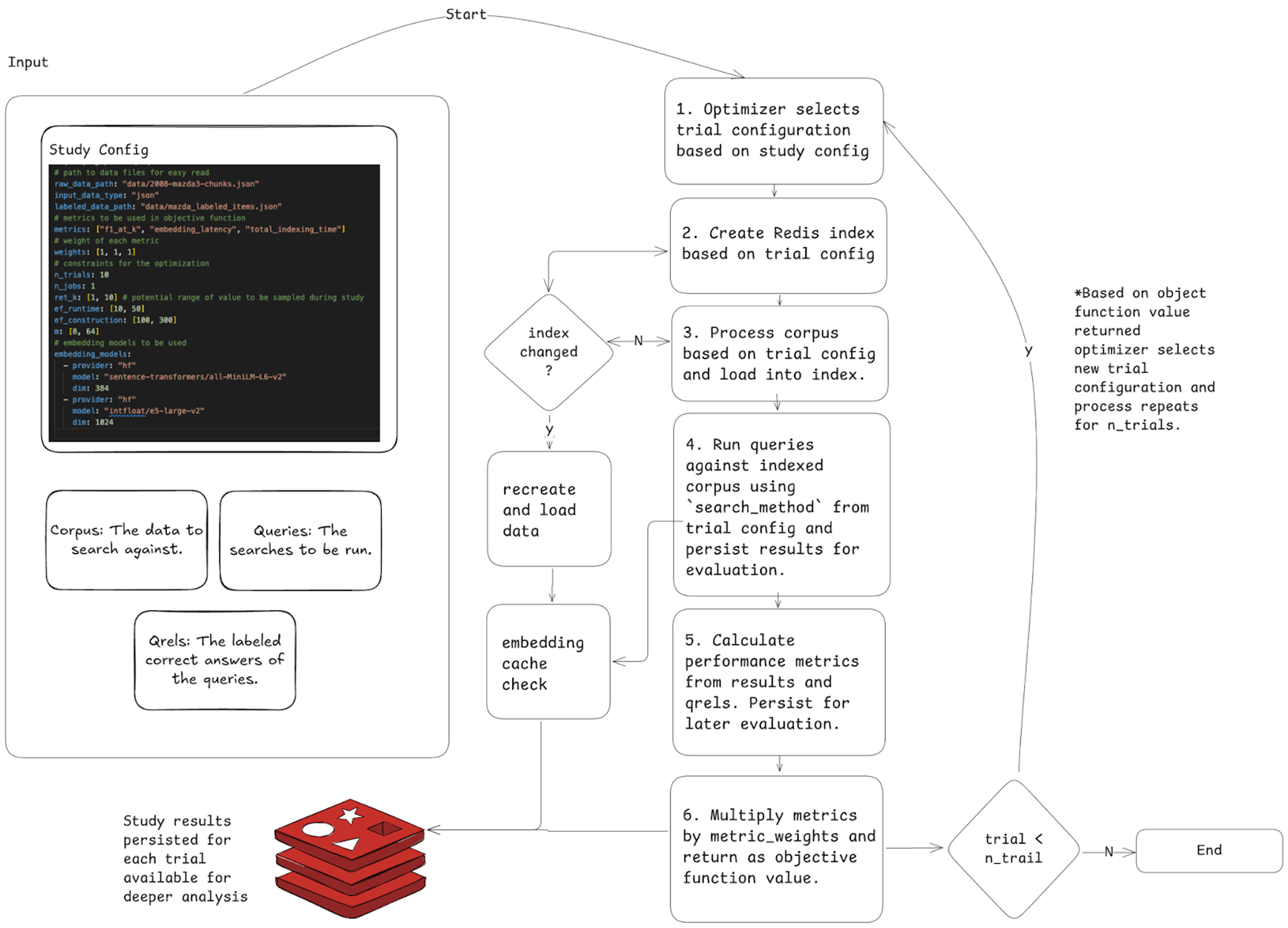
Process schematics
The following diagram outlines the full process flow for how the retrieval optimizer completes bayesian optimization. The retrieval optimizer uses the Redisvl embedding cache feature and only re-indexes when needed. This makes it much faster to run later tests.
Next steps
Hopefully you’re now well on your way to optimizing your retrieval process. You can see the full notebook example of this tutorial here and the source code for the retrieval optimizer here.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.