
One of the most valuable pieces of feedback I’ve ever received as an engineer came as an intern. I was debugging some data issues and, truthfully, didn’t really know what was going on. When my manager asked me for an update, I responded with something vague like, “I think it happens when event A occurs, but not all the time—so maybe it’s a network thing?”
He looked at me, in the way senior engineers will look at junior engineers for the rest of eternity, smiled and said: “Well don’t guess—measure the problem.”
At the time, it felt like a small correction. But as I’ve grown in my career, I’ve seen over and over how much time and effort is wasted because we guess—about root causes, about what matters, about what’s better—without grounding those guesses in real measurements or clear goals. I’ve wasted countless hours of my life debugging assumptions, and when I’m stuck I will often find myself repeating the phrase “don’t guess” like a mantra. I suppose that’s sort of absurd, but it works for me.
Recently, I was working with a large financial services customer trying to improve the performance of a retrieval-augmented generation (RAG) system. They were chasing a “silver bullet”: a better model, a novel chunking strategy, a fancy retrieval trick they saw in a blog post. We tried a dozen things, and each had some effect, but no one could confidently say what was actually helping, and by how much. We were optimizing vibes, not metrics.
This isn’t unusual. Our team at Redis has interactions daily with devs and product teams who are asking similar kinds of questions: What embedding model should I use? What’s the best retrieval method? These are good questions—but the unfortunate (and unsatisfying) answer is almost always: it depends. Everyone we talk to has slightly different business requirements, slightly different data, and while there are general best practices, it still feels more like name dropping than true engineering.
Eval Driven Development (EDD)
Traditional software is largely deterministic—click button A, get result B—and can be reliably tested with unit and integration tests. LLM-based apps, however, are probabilistic by nature, making consistent behavior harder to guarantee. This has led to the rise of eval-driven development (EDD), where teams define clear metrics and use structured evaluation sets to measure and iterate on model performance.
This is where the Retrieval Optimizer comes in. We built a way to flexibly test the parts of their system that drive what depends. The Retrieval Optimizer is an open source framework that makes it quick and easy to measure performance for your specific situation. It also compares configurations objectively, in their own setting, against the metrics that are important for your problem.
Specifically, with the retrieval optimizer you can try multiple embedding models, test different retrieval methods (BM25, hybrid, rerank, vector search, and more), and run evaluations on curated IR datasets or bring your own. The output of which is a meaningful profile of the options—grounded in actual data, not just intuition.
Ironically, once you’ve defined your goals clearly and made them measurable, then you can afford to guess. Try things out quickly. Iterate. Explore. Because now, every guess becomes a test—and every test gives you a signal of the right direction to go.
Furthermore, as more and more code and processes integrate AI the new bottleneck in development will increasingly be verification, as Andrej Karpathy points out in his keynote at the AI startup school. Tools like the retrieval optimizer help reduce the bottleneck of verification by providing a framework for quicker evaluation, aka verification of a probabilistic process.
Code or it didn’t happen
📓A complete example notebook is available here.
The easiest way to get started with the retrieval optimizer is to run a grid study. With a grid study, you choose the embedding models and search methods you want to test. The retrieval optimizer runs them in a row like a grid search, which is why the name is given.
The retrieval optimizer will do the work of embedding, indexing, and searching against your provided corpus data. This will let you focus on the new search part of your problem.
Steps
Install tool:
Run redis:
Prepare dataset:
For ease of getting started we are going to use the nfcorpus dataset made easily available through beir-cellar for benchmarking IR. In this example, we’ll use the useful NF Corpus dataset (Non-factoid corpus). This dataset is a biomedical based dataset that is often used for testing longer answers that need understanding beyond simple fact-based queries.
Corpus
The Corpus is the full set of documents you'll be searching against, i.e. what gets indexed into Redis. By default, this data will be processed by the corpus_processors.eval_beir.process_corpus function, which knows how to format data from these general IR benchmarks. You can also define your own custom processors to handle corpus data provided in a different structure. For an example, see this blog.
General structure:
Real world example:
Queries
Queries are the search inputs you'll evaluate against the corpus. Each query should have a unique ID and the query text. Like the corpus, you can define your own query structure and objects and use custom search methods. For an example, see this blog.
General structure:
Example:
Qrels
Qrels, otherwise known as query relevance judgments, are a formalized way of defining the relevance of documents for each query under test. The format is used by many IR benchmarking tools and was first introduced by TREC. For the retrieval optimizer, the format is required for evaluating retrieval performance using metrics like NDCG, recall, precision, and F1. In brief, Qrels act as “ground truth” for the retrieval optimizer and must follow this structure for the optimization to work as expected.
Required structure:
Example:
Define a study YAML
The study config is where you configure the parameters under test and looks like this:
Run a grid study
Once the data is in place and the study_config file, executing the study becomes trivial. Simply import the function, pass the variables, and execute the function. From here, the retrieval optimizer will iteratively run each search method for each embedding model and collect the corresponding results.
Output and analysis
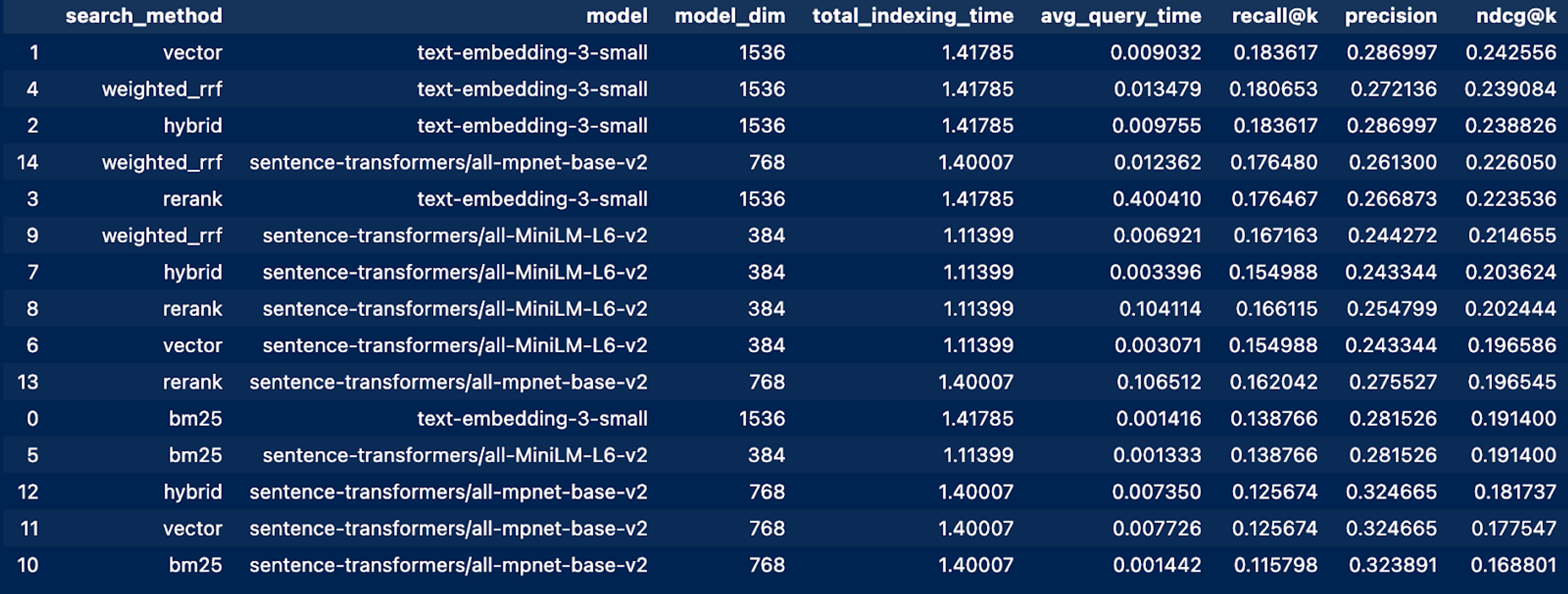
Once complete the metrics variable, shown in the last code block, will be a dataframe containing key information about the average time for each query, overall indexing time, as well as recall, precision, and normalized discounted cumulative gain (ndcg).
From this grid study, we can say that the embedding model had more impact on the overall performance of our retrieval than did the search method. The top 3 results all used OpenAi’s text-embeeding-3-small over the hugging face alternatives. However, this is where the real engineering begins and we can start to offer informed opinions. For example, we can see that using weighted_rrf with the all-mpnet-base-v2 model had the same accuracy as the top 3. But maybe for the system we’re measuring that’s good enough to justify the cost savings of an open source model over hitting the OpenAI service.
Next steps
Hopefully in this blog I have effectively motivated the need for Eval Driven Development and highlighted the value that the retrieval optimizer can provide your team. Beyond this first use-case of determining our model and search method selection, the retrieval optimizer can also perform more complex index fine-tuning with bayesian optimization. To see how, when, and why to check that out, see this blog.
A full notebook example of the code above is available here. To follow more of what the Applied AI team is up to at Redis check out the redis-ai-resources repo.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.