Blog
Why your caching strategies might be holding you back (and what to consider next)

Caching is the process of storing copies of data in temporary storage, allowing new requests for that data to be served more quickly. Without that temporary storage – the cache – requests would take longer. With a cache, systems can retrieve commonly used data in milliseconds or less.
Caching has been around for a long time, but it’s only gotten more important as user expectations for speed have risen. Back in 2013, researchers found that the median load time for first-time visitors to a retail website’s home page was 7.25 seconds – an enormously long wait time to imagine enduring today. In 2024, researchers found that the average web page load time on desktop was now a mere 2.5 seconds.
User expectations keep growing, and on the backend, these expectations can conflict: Users want faster and faster services, even though they also want dynamic, interactive, real-time experiences. Complexity grows, and yet, speed has to grow, too. Enter caching.
Caching is not a new concept, but implementing and scaling it has become increasingly challenging in parallel with the general complexity of the web. The relatively new popularity of microservices has made caching a constraint for many companies, and the rise of generative AI poses even more latency risks.
Caching is not a purely technical decision. We’ll walk you through the basics, the benefits, and explain different caching strategies and their tradeoffs. Ultimately, to develop a robust and reusable approach to caching, enterprises must work backward from the use case and the business case they’re facing to determine an ideal balance between performance and cost savings.
What is caching, and why is it important?
Caching is a performance optimization technique that stores frequently accessed data in a high-speed storage layer to reduce latency. It shows up at many layers of a system, from browser-level caching of static assets to backend services storing data for faster access.
This article focuses on application and database caching, where frequently used values, query results, or session data are stored in memory to reduce load on primary databases and improve response times.
This type of caching is especially valuable in modern applications, where responsiveness, scalability, and real-time experiences are essential.
Let’s say a user is on a retailer’s website and decides to add a product to their cart. The price is calculated immediately because the cart is in the cache, and the website has already loaded the user’s location and calculated the applicable tax rates. That value, along with the cart, can be cached, allowing the website to re-access it repeatedly without needing to recalculate it. This is a relatively simple calculation, but the same logic is increasingly beneficial when there are more calculations or more complex calculations.
Benefits of caching
The closer your updates need to be to real-time and the more frequently users need to access the same data repeatedly, the more important caching – and your particular choice of caching strategies – becomes.
A good caching strategy provides major benefits to end-users and to the developers who maintain the database that supports them. The primary benefits include:
- Improved performance and reduced latency: When cached, responses can be served in-memory, often delivering at a 10x to 100x faster rate than possible from disk-based database queries.
- Reduced database loads and costs: Caching reduces the number of queries sent to the database, resulting in a lower load on expensive backend systems. Cached data is also served locally, allowing companies to save on egress costs with cloud providers.
- Improved user experience: Caching reduces latency, making users less likely to bounce due to a slow experience.
- Greater scalability: Caching enables systems to handle higher query volumes without proportionally increasing database capacity, allowing them to scale more smoothly, even in the face of load spikes.
- Better fault tolerance: Caches can serve as stale-but-acceptable data during outages or high-latency events, supporting high-availability setups with high-performance requirements.
The benefits of caching are undeniable, which is why caching, at its most basic, is so popular — and has been for so long. Like the foundation to a house, however, the difference between a solid foundation and an unstable one can have dramatic effects down the line. Similarly, the differences between various caching strategies can result in significantly different benefits and trade-offs.
5 signs you need a better caching strategy
An enterprise’s caching strategy is frequently one of those problems. The trouble is that caching is an easy box to check, but it’s not always clear whether the caching strategy in play is as effective as it needs to be. Again, like the foundation to a house, the first sign isn’t always obvious, but if you look closely, you can trace subtle cracks in the walls back to their source.
Instead of assuming caching is done and good enough, look for these signs and trace them back to caching – your caching strategy might not be working as well as you thought.
- Are read queries dominating database load? The more repetitive the queries, the more likely your caching strategy isn’t keeping up.
- Are systems suffering from unpredictable latency spikes? If the amount of data being requested hasn’t changed dramatically, but your systems are enduring high p90/p99 latency levels, then those performance issues can often be traced back to caching.
- Do you frequently hit rate limits with your database provider? A good caching strategy stores commonly used data locally.
- Is performance lower than expected, especially during spikes? A good caching strategy offloads the most frequent read requests to a provider optimized for rapid retrieval, like Redis.
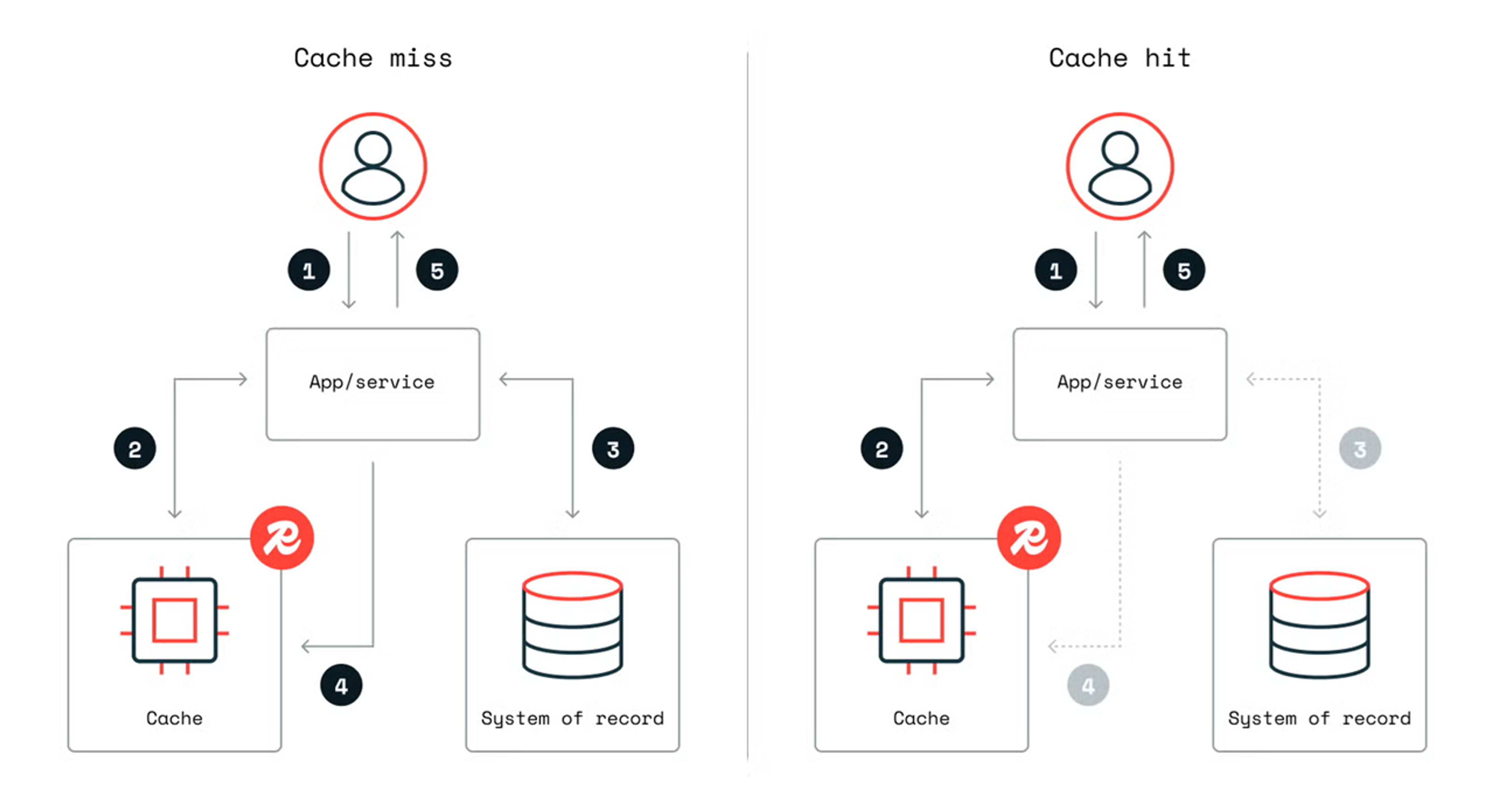
- Is your cache hit rate low? A low hit rate can lead to more queries hitting the database, which increases latency and causes downstream performance issues.
The more of these signs you start to see, the more likely you need to reassess your caching strategy.
Caching strategies: An overview
There is a wide range of caching strategies to choose from, each varying in effectiveness and complexity.
The primary differences tend to revolve around how the caching approach handles cache misses, when the system attempts to retrieve data from a cache and the data isn’t available, what happens with database writes and data expires, and implementation, which can vary depending on the complexity of the systems in question and the use cases at hand.
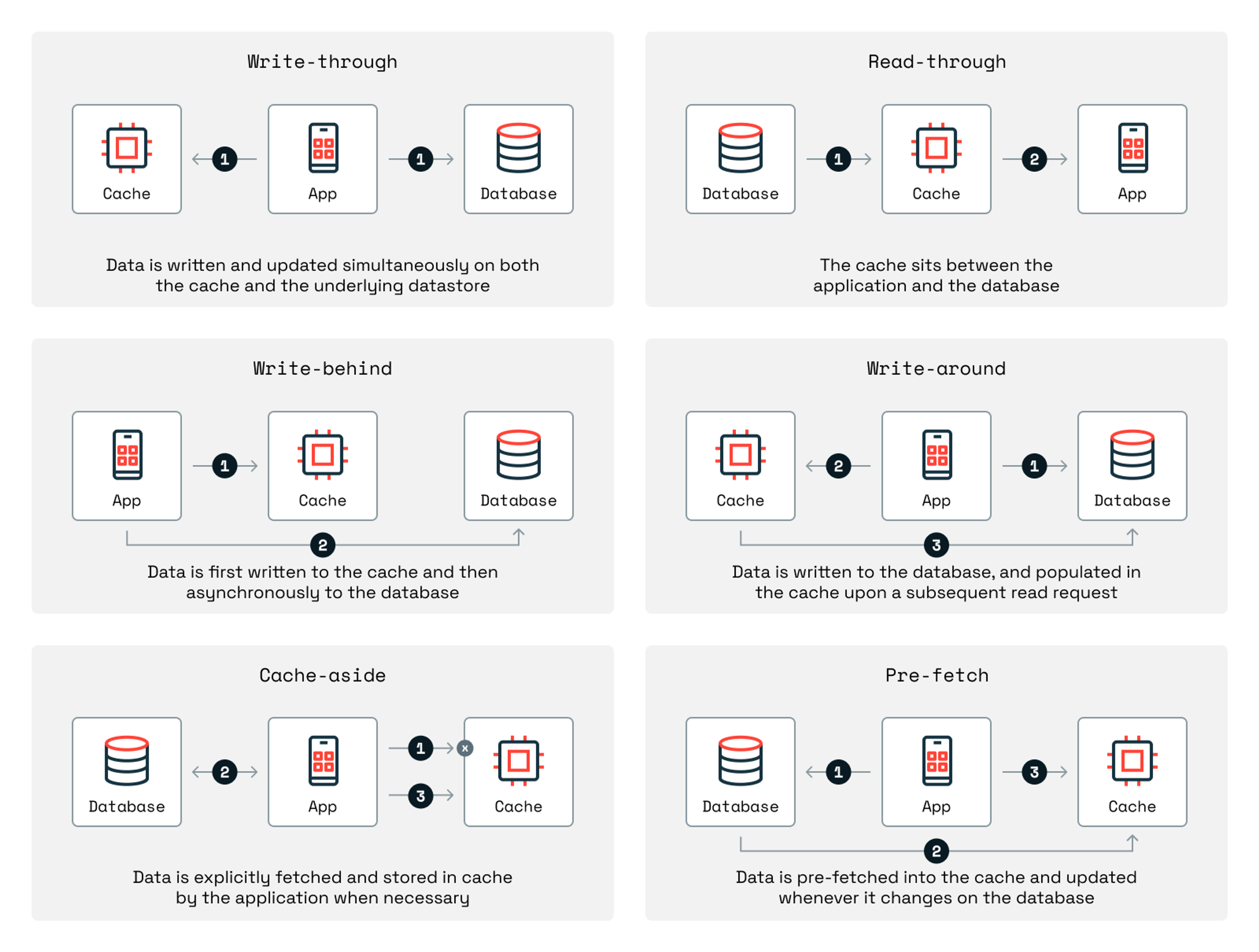
Read-through cache
A read-through cache is a caching strategy where the cache itself fetches data from the underlying database whenever a cache miss occurs and stores the results in the cache.
This caching strategy is relatively easy to implement, abstracts the data retrieval process from the underlying application, and improves performance for frequently accessed data. This strategy is best for read-heavy applications with consistent access patterns.
Write-through cache
A write-through cache is a caching strategy in which writes are sent to both the cache and the database simultaneously.
This caching strategy poses tradeoffs: On the one hand, it keeps the cache fresher than other strategies; on the other hand, it adds write latency. There’s also risk. If the cache write succeeds but the database fails, or vice versa, then there’s a data inconsistency that needs to be resolved.
Cache-aside (lazy loading)
In a cache-aside approach, also known as lazy loading, the application directly manages the cache. Data is only loaded into the cache when necessary, which typically means after a cache miss.
Lazy loading is the most flexible caching strategy because the application dictates the caching behavior, allowing companies to tailor caching to their specific applications. As a result, lazy loading is one of the most commonly used patterns you’ll see in use.
There are tradeoffs, however: The first query to uncached data tends to suffer from latency, for example, and without proper invalidation, the cache can serve outdated information. Lazy loading tends to be best for read-heavy applications, where systems frequently read data but infrequently update it.
Write-behind (write-back) cache
In a write-behind approach, also known as write-back, writes are first made to the cache and then asynchronously written to the underlying database after a prespecified delay.
This strategy improves write performance by decoupling the application’s write operations from any latency caused by the persistent storage. There is, however, a risk of data loss if the cache fails before writing data to the database. Implementation can also be difficult because this approach requires mechanisms to handle retries, failures, and eventual consistency.
Expiry-based caching
In expiry-based caching, a specific lifespan is assigned to cached data. Expiry-based caching uses time-to-live (TTL) to measure the time an asset is cached before it's deleted. Once this timespan ends, the system considers cached data stale and either removes it or refreshes it from the original data source.
This approach can work well in contexts where data doesn’t need to be real-time. By serving repeated requests from the cache within the TTL window, this strategy reduces the frequency of direct queries to the main data source, which decreases the overall database load. If the TTL window is too long, however, the data can get stale.
Cache pre-fetching
In a cache pre-fetching approach, cached data is updated or removed in response to specific events in the underlying database. Changed data is identified, transformed, and ingested into the cache, ensuring the cache continuously updates itself based on changes to the underlying database. Data is effectively pre-fetched, the source of the name, before the app requests it.
This approach helps ensure that the cache remains consistent with the database while also providing users with outputs without relying on time-based expiration, as in the previous approach.
This approach supports strong consistency, but it’s complex. Event-driven systems require significant upfront investment, making it difficult to do yourself, but some caches, including Redis (with RDI), have it built in.
How caching strategies shift for write-heavy use cases
Caching is most well-known for supporting read-heavy use cases. These are the times when users tend to request the same information repeatedly – think static assets, such as HTML files, or user session data, such as authentication tokens.
As a result, write-heavy use cases tend to be overlooked, and caching approaches that support read-heavy use cases can collapse when presented with new, write-heavy requirements.
Take interactive user sessions, for example, where users might be typing comments into a comment box, writing messages, communicating with chatbots, adding products to shopping carts, or playing an online game.
In use cases like these, it’s more important that the data gets to the front end of the application and the end-user than it is to store the data in a database for later use. In write-heavy use cases like these, the priority is delivering the message, not storing it durably, which makes your caching strategy paramount.
Take financial systems, for another example. Many financial businesses have to constantly, reliably, and quickly stream data about shares, securities, and transactions. Markets rely on up-to-date information, and companies can become dramatically less useful to their customers if they cannot keep them informed about the latest developments.
In use cases like these, latency can damage, if not destroy, the usefulness of a real-time updates system.
That’s why Deutsche Börse Group, an international exchange organization and market infrastructure provider, uses Redis as an intelligent cache for processing and organizing data for reporting purposes. “Redis supports the throughput and latency requirements Deutsche Börse is required to guarantee to its regulator and the customers,” reports Maja Schwob, Head of Data IT at Deutsche Börse.
Monitoring and observability for caching
No caching strategy is “set it and forget it.” To maintain performance and keep latency down to acceptable levels, companies need to monitor metrics and make observability-driven caching decisions.
Key metrics include:
- Cache hit rate: The proportion of requests served by the cache instead of the database.
- Eviction rate: The frequency with which a cache removes items to make space for new data. High eviction rates can indicate that the cache is too small for the workload or that the eviction policy is misconfigured.
- Latency: The length of time a user or system waits between sending a request and receiving a response.
- Error rates: The percentage of cache operations that fail due to issues like timeouts, connection problems, or internal errors.
Tools that can help with observability include:
- Built-in tools and metrics
- Distributed tracing tools, such as OpenTelemetry, can help you spot bottlenecks.
- Metrics dashboards, such as Prometheus and Grafana, can help monitor cache usage.
- Logging tools that can help you monitor patterns in cache usage.
- Application performance monitoring systems help you identify constraints that could be hampering performance.
Once you choose a caching strategy that suits your use case, you can monitor it over time, iterate to improve it, and identify any potential issues that might make a different approach more effective.
Redis vs. built-in caching
“Correct caching,” in the words of Scott Hanselman, Vice President of Developer Community at Microsoft, “is always hard.” While experimenting with the service that hosts his podcast, Hanselman found himself “getting close to making [his] own implementation of Redis here.”
This is a dynamic that most developers and architects are familiar with: Unlike many other roles, developers can build their own tooling, meaning every tool involves a build vs. buy decision.
The tricky element, when it comes to caching, is that most developers agree caching isn’t worth building (“Problem solved, crisis averted, lesson learned. Don't be clever [...] Never implement your own caching,” writes programmer Swizec Teller). Many are unaware, however, of the limitations involved in using built-in caching compared to a standalone provider like Redis.
Built-in caching features are often tied to specific databases. PostgreSQL, for example, includes a shared buffer cache that stores frequently accessed table and index data in memory. These features work well for basic read optimization on a single-node database.
But built-in caches quickly run into limitations at scale. They are difficult to use in distributed environments, where consistency, invalidation, and coordination across services become critical. Memory is typically scoped to a single database instance, which may be fine for small applications or monoliths, but it breaks down when multiple systems need fast access to shared data. In those cases, an external caching layer provides more flexibility, control, and scalability.
A standalone solution, such as Redis, is often a better choice when you’re building high-scale, distributed systems. Redis works across microservices and multi-language environments, and supports advanced caching strategies, eviction control, durability, and fine-grained performance tuning. Redis also provides:
- Shared cache across services.
- High write and read volume.
- Complex caching logic.
- Long-term or persistent caching.
The choice is context-dependent, and companies will make the best decision by working backward from the business and use cases they’re facing. Throughout, consider the tradeoffs:
- Latency: Framework caches tend to feel faster locally, but Redis offers sub-millisecond access at scale, which is when built-in caches often struggle.
- Scalability: Built-in caching doesn’t scale well across services, but Redis can scale across multitudes of services. CheQ, for example, uses Redis to support over 10 million transactions across more than 50 microservices.
- Observability: Built-in caching rarely supports fine-grained observability, but Redis supports cache hit/miss metrics, eviction stats, and APM integrations.
- Durability: Built-in caches typically live only in memory or process-local, but Redis can persist cache state.
- Cache sharing: Redis, unlike built-in options, can act as a shared memory layer across APIs, workers, and services.
In many cases, built-in caching is the simpler option, but if you want to scale – and scale reliably – a standalone service like Redis is often the better choice.
Caching with Redis
Redis provides a fast, highly available, resilient, and scalable caching layer that works across clouds, on-premises, and hybrid environments, allowing real-time apps to run at enterprise scale. Redis in-memory caching enables
- Sub-millisecond latency for real-time applications.
- Hybrid and multi-cloud deployment options.
- Linear scalability without performance degradation.
- High availability with 99.999% uptime.
- Cost efficiency through multi-tenancy and storage tiering.
- Advanced caching patterns, such as write-through, write-behind, and prefetching.
- Redis Data Integration (RDI), a tool that synchronizes data from your existing database into Redis in near real time.
To see how Redis caching can support high-performance systems, try Redis for free.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.